




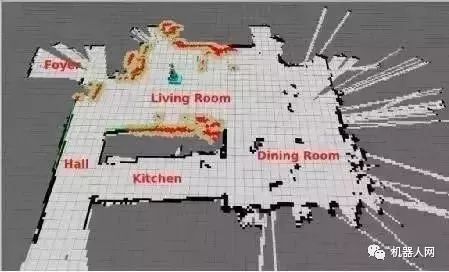
谈到移动机器人,大家第一印象可能是服务机器人,实际上无人驾驶汽车、可自主飞行的无人机等等都属于移动机器人范畴。它们能和人一样能够在特定的环境下自由行走/飞行,都依赖于各自的定位导航、路径规划以及避障等功能,而视觉算法则是实现这些功能关键技术。
如果对移动机器人视觉算法进行拆解,你就会发现获取物体深度信息、定位导航以及壁障等都是基于不同的视觉算法,本文就带大家聊一聊几种不同但又必不可少的视觉算法组成。
移动机器人的视觉算法种类
问:实现定位导航、路径规划以及避障,那么这些过程中需要哪些算法的支持?
谈起移动机器人,很多人想到的需求可能是这样的:“嘿,你能不能去那边帮我拿一杯热拿铁过来。”这个听上去对普通人很简单的任务,在机器人的世界里,却充满了各种挑战。为了完成这个任务,机器人首先需要载入周围环境的地图,精确定位自己在地图中的位置,然后根据地图进行路径规划控制自己完成移动。
而在移动的过程中,机器人还需要根据现场环境的三维深度信息,实时的躲避障碍物直至到达最终目标点。在这一连串机器人的思考过程中,可以分解为如下几部分的视觉算法:
1.深度信息提取
2.视觉导航
3.视觉避障
后面我们会详细说这些算法,而这些算法的基础,是机器人脑袋上的视觉传感器。
视觉算法的基础:传感器
问:智能手机上的摄像头可以作为机器人的眼睛吗?
所有视觉算法的基础说到底来自于机器人脑袋上的视觉传感器,就好比人的眼睛和夜间视力非常好的动物相比,表现出来的感知能力是完全不同的。同样的,一个眼睛的动物对世界的感知能力也要差于两个眼睛的动物。每个人手中的智能手机摄像头其实就可以作为机器人的眼睛,当下非常流行的Pokeman Go游戏就使用了计算机视觉技术来达成AR的效果。
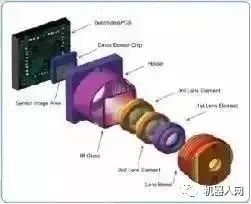
像上图画的那样,一个智能手机中摄像头模组,其内部包含如下几个重要的组件:镜头,IR filter,CMOS sensor。其中镜头一般由数片镜片组成,经过复杂的光学设计,现在可以用廉价的树脂材料,做出成像质量非常好的手机摄像头。
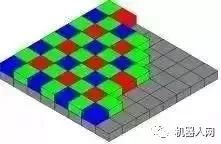
CMOS sensor上面会覆盖着叫做Bayer三色滤光阵列的滤色片。每个不同颜色的滤光片,可以通过特定的光波波长,对应CMOS感光器件上就可以在不同位置分别获得不同颜色的光强了。如果CMOS传感器的分辨率是4000x3000,为了得到同样分辨率的RGB彩色的图像,就需要用一种叫做demosaicing的计算摄像算法,从2绿1蓝1红的2x2网格中解算出2x2的RGB信息。
一般的CMOS感光特性除了选择红绿蓝三色之外,对于红外光是透明的。因此在光路中加上IR滤光片,是为了去除太阳光线中红外光对CMOS的干扰。加上滤光片后,通常图像的对比度会得到显著的提升。
问:计算机视觉中还会用到什么传感器?
除了RGB相机,计算机视觉中常用的还有其他种类的特殊相机。例如有一种相机的滤光片是只允许通过红外光波段的。因为人眼通常是看不见红外光的,所以可以在相机附近加上主动红外光源,用于测距等应用。

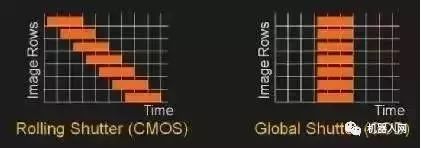
另外,大部分我们用到的camera都是以rolling shutter的形式实现电子曝光的,像图中左侧那样,为了减少电子器件的成本,曝光通常是一行一行分别进行,这样势必造成物体快速移动时,相机采集到的图像会发生形变。为了避免这种形变对基于立体几何进行计算的视觉算法的影响(例如VSLAM),选用global shutter的相机就显得特别重要了。

深度相机是另一大类视觉算法中需要的传感器,可以分成如下几类:
1.TOF传感器(例如Kinect 2代),类似昆虫复眼。成本高,室外可以使用。
2.结构光传感器(例如Kinect 1代),三角定位原理,成本中,室外不能用。
3.双目视觉(例如Intel Realsense R200),主动照明或被动照明,IR或可见光皆可。成本低,室外可以使用。
算法一:深度信息提取
问:深度相机如何识别物体的深度信息的呢?
简而言之,其原理就是使用两个平行的相机,对空间中的每个点三角定位。通过匹配左右两个相机中成像点的位置,来计算对应三维点在空间中的距离。学术界对双目匹配恢复深度图研究有很长的历史,在NASA火星车上就开始采用这个技术。但是其真正在消费电子品市场得到广泛应用还是从微软的Kinect体感传感器开始。
Kinect传感器背后使用了以色列Primesense公司授权的结构光技术(如今已被Apple收购)。其原理是避开双目匹配中复杂的算法设计,转而将一个摄像头更换成向外主动投射复杂光斑的红外投影仪,而另一个平行位置的相机也变成了红外相机,可以清楚的看到投影仪投射的所有光斑。因为人眼看不到红外光斑,而且纹理非常复杂,这就非常有利于双目匹配算法,可以用非常简洁的算法,识别出深度信息。
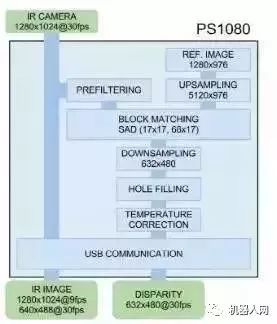
尽管Kinect的内在原理官方并没有给出解释,在近年来一篇Kinect Unleashed的文章中,作者向公众hack了这个系统的工作原理:
首先,红外图像在基线方向上采样8倍,这样可以保证在做双目匹配后实现3bit的亚像素精度。然后,对图像做sobel滤波,使得图像的匹配精度提高。而后,图像与预存的投影光斑模板图像进行SAD block matching。该算法的计算复杂度小,适合硬化和并行。最后,经过简单的图像后处理,下采样到原始分辨率,得到最终的深度图。
我们可以看到,随着2009年Kinect设备在消费机市场的爆发(发售头10天100万台),逐渐开始催生了类似技术变种在移动端设备的研发热潮。从2013年至今,随着计算能力的提升和算法的进步,硬件成本更低的主动/被动双目深度相机开始在移动手机上涌现。

过去认为很难实时运行的双目匹配算法,即使在没有主动结构光辅助的情况下,也表现出非常优异的3D成像质量。SegwayRobot采用了主动/被动可切换的双目深度视觉系统。如下图所示,左侧三个传感器分别为,左红外相机,红外pattern投影,右红外相机。在室内工作时,因为红外光源不足,红外投影打开,辅助双目匹配算法。在室外工作时,红外光源充足,红外投影关闭,双目匹配算法可以直接运行。综合看,此系统在室内外都表现出优异的深度传感能力。

算法二:定位导航
问:视觉处理后,机器人是如何实现导航的?
机器人导航本身是一个比较复杂的系统。其中涉及到的技术会有如下列表:
视觉里程计 VO
建图,利用VO和深度图
重定位,从已知地图中识别当前的位置
闭环检测·,消除VO的闭环误差
全局导航
视觉避障
Scene tagging,识别房间中物体加上tag
机器人开机,视觉里程计就会开始工作,记录从开机位置起的6DOF定位信息。在机器人运动过程中,mapping算法开始构建机器人看到的世界,将空间中丰富的特征点信息,二维的地图信息记录到机器人map中。
当机器人运动过程中因为遮挡、断电等原因丢失了自身的坐标,重定位算法就需要从已知地图中定位到机器人当前的位置估计。另外,当机器人运动中回到了地图中曾经出现过的位置,往往视觉里程计的偏差会导致轨迹并没有完全闭合,这就需要闭环算法检测和纠正这个错误。
有了全局地图之后,机器人就可以给定一些目标点指令,做全局的自主导航了。在现实中,因为环境是不停变化的,全局地图并不能完全反映导航时的障碍物状况,KUKA机器人维修,因此需要凌驾于全局导航之上的视觉避障算法进行实时的运动调整。
最后,一个自动的导航系统还需要机器人自动识别和理解空间中的不同物体的信息、位置、高度和大小。这些tag信息叠加在地图上,机器人就可以从语义上理解自己所处的环境,而用户也可以从更高层次下达一些指令。
问:视觉VSLAM在机器人上的实现有哪些难点?
视觉VSLAM是一个集合了视觉里程计,建图,和重定位的算法系统。近年来发展很快。基于特征的视觉SLAM算法从经典的PTAM算法开端,目前以ORB-SLAM为代表的算法已经可以在PC上达到实时运行。下面是一个ORBSLAM的框图:
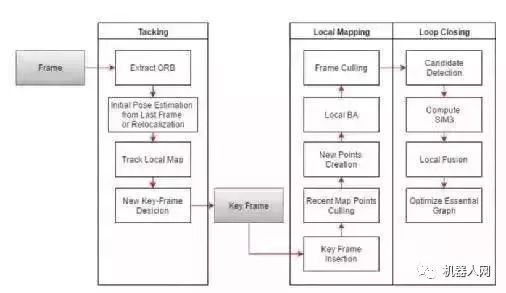
从名字可见,其使用ORB作为图像特征提取工具,并且在后续的建图及重定位中均使用了同一份特征点信息。相对于传统的SIFT和SURF特征提取算法,其效率高出很多。
ORB-SLAM包含三个并行的线程,即跟踪,建图和闭环。其中跟踪线程运行在前端,保证实时运行,建图和闭环线程运行在后端,速度不需要实时,但是与跟踪线程共享同一份地图数据,可以在线修正使得地图数据精度和跟踪精度更高。下图是ORB-SLAM地图的主要数据结构,
点云和关键帧。两者之间通过图像上2D特征点与空间中的点云建立映射关系,同时还维护了关键帧之间的covisibility graph关系。通过这些数据关联,用优化方法来维护整个地图。

ORB-SLAM在机器人上应用仍然存在如下难点:
1.计算量过大,在4核处理器上通常会占去60%左右CPU资源。
2.在机器人运动过快时会出现跟丢不可复原的情况。
3.单目SLAM存在尺度不确定的问题。在机器人快速旋转时,此问题尤其明显,很快会出现闭环误差过大无法纠正的情况。
针对尺度问题,有两种方法解决:增加一个摄像头形成双目SLAM系统,或者增加一个IMU形成松耦合/紧耦合的视觉惯导定位系统。这里简单介绍松耦合的视觉惯导定位系统。一般把VSLAM当成一个黑盒子,将其的输出作为观测量放到一个基于IMU的EKF系统中,EKF最终fuse的输出即是系统的输出。
考虑到camera数据和IMU数据通常是不同步的,因此通过硬件时间戳,KUKA机器人维修,需要判断图像数据对应的时间戳与IMU时间戳的关系。在EKF propagate步骤,更高帧率的IMU数据不停的更新EKF的状态。在camera数据到来时,触发EKF update步骤,根据EKF建模方程来更新状态变量、协方差矩阵,并且重新更新所有晚于camera数据的IMU数据对应的状态变量。
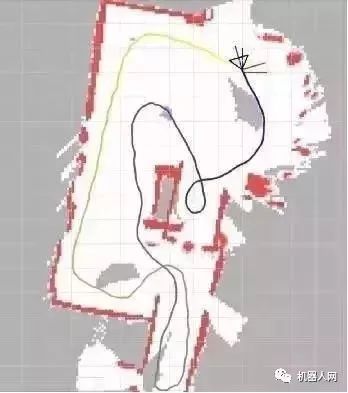
SegwayRobot采用了业界领先的视觉惯导定位系统,下面是一个在楼道里面运行一圈,回到原点之后的效果图,具体有如下优势:
1.在大尺度下可以保证非常小的闭环误差
2.实时运行,需求CPU资源小
算法三:避障
问:视觉避障的算法原理是怎样的?
导航解决的问题是引导机器人接近目标。当机器人没有地图的时候,接近目标的方法称为视觉避障技术。避障算法解决的问题是根据视觉传感器的数据,对静态障碍物、动态障碍物实现躲避,但仍维持向目标方向运动,实时自主导航。
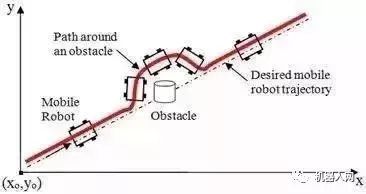
避障算法有很多,然而这些方法都有严格的假设,假设障碍物为圆形或假设机器人为圆形,假设机器人可以任意方向运动,s或假设它只能走圆弧路径。然而实际应用上,机器人很难达到条件。比如VFF算法, 该算法假设机器人为点,而且可以任意方向运动。VFH+假设机器人为圆形,通过圆形膨胀障碍物,在考虑运动学问题时仅仅假设机器人以圆弧路径运动。DWA也假设机器人为圆形,在考虑运动学问题时只模拟了前向圆弧运动时的情况。
相对而言,我们不限制机器人的形状,考虑运动学问题时,模拟多种运动模型,而不限于圆弧运动,因为这样可以为机器人找到更佳避开障碍物的行为。
这张图显示了使用不同运动学模型导致不同的避障结果。左图表示使用圆弧模型时模拟的路径,右图表示使用另一种路径模型模拟的路径。在这种狭小环境,此方法可以提前预测多个方向的障碍物情况,选择合适的模型可以帮助找到更合适的运动方向躲避障碍物。
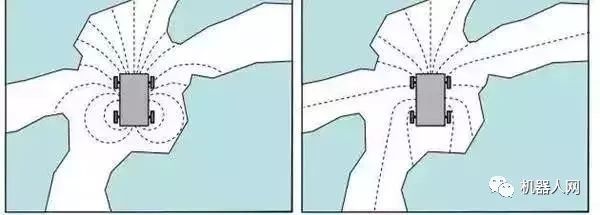
和目前常用的避障算法之间存在的差异在于,它将运动学模型抽象化到周围环境地图中,然后就可以使用任何常用的避障算法,这样就解耦了运动学模型与算法的捆绑,而且任何要求严格的避障算法都能加入进来。SegwayRobot的避障系统,综合了深度传感器,超声波,IMU等sensor。在复杂的环境中,可以自如躲避障碍物。

这张图是我们的避障系统的一个截图,可以看到深度图和2维的避障地图。最下面红色的指针就代表了每时每刻避障的决策。
精彩问答
Q:为什么选用ir相机而不是传统的rgb相机呢?ir相机相对来讲的优势在哪里?
A:ir相机可以看到人眼看不到的物体,比如深度相机需要在室内投射红外纹理,帮助深度识别。人眼看不到,但ir相机可以看。
Q:现在机器人导航是否主要是slam技术,还有没其他导航技术?主要流行的slam技术有哪些?用于无人驾驶和无人机的视觉导航技术有哪些异同?
A:slam技术是导航中的一个基础模块,种类很多,有单目,双目,depth,imu+视觉等传感器为基础的算法。双目相机可以很好的适应室内和室外的环境。他的体积其实非常小,segwayRobot使用的camera长度在10cm左右
Q:现在有无用于机器人导航的导航地图存在,类似车载导航地图?用于机器人导航的地图数据有哪些?